Apache Kafka has emerged as a pivotal technology in the realm of distributed streaming platforms, empowering organizations to build robust, scalable, and fault-tolerant real-time data pipelines and streaming applications. This article provides a comprehensive exploration of Kafka, delving into its core concepts, architecture, use cases, implementation examples, and practical considerations.

A. What is Apache Kafka?
At its core, Apache Kafka is a distributed streaming platform designed to handle high-volume, real-time data feeds. It operates as a publish-subscribe messaging system, enabling applications to produce (publish) and consume (subscribe) data streams. Kafka's architecture is optimized for high throughput, fault tolerance, and scalability, making it suitable for a wide array of applications, from log aggregation and real-time analytics to data integration and stream processing.
Unlike traditional messaging systems that typically discard messages after consumption, Kafka persists messages on disk, allowing multiple consumers to access the same data stream without impacting each other. This persistent storage model, coupled with Kafka's distributed nature, ensures data durability and availability, even in the face of hardware failures or network disruptions.
1.1) Why Apache Kafka?
.png)
Apache Kafka's rise to prominence stems from its unique combination of features that address the challenges of modern data architectures. Here's a breakdown of why it's so widely adopted:
1. Real-Time Data Streaming:
Modern applications generate a constant stream of data. Kafka excels at ingesting, processing, and delivering this data in real-time.This is crucial for applications like fraud detection, real-time analytics, and activity tracking, where immediate insights are essential.
Traditional batch processing systems are ill-suited for these scenarios. Kafka enables continuous data flow, empowering organizations to react to events as they happen.
2. High Throughput and Scalability:
Kafka is designed to handle massive volumes of data with minimal latency.Its distributed architecture allows it to scale horizontally by adding more brokers to the cluster.
This scalability makes it ideal for applications that generate a high volume of data, such as log aggregation, sensor data processing, and clickstream analysis.
3. Fault Tolerance and Durability:
Kafka replicates data across multiple brokers, ensuring data durability and availability even if some brokers fail.
This fault tolerance makes it a reliable platform for critical applications that cannot afford data loss.
Kafka persists data to disk, offering a robust storage mechanism.
4. Publish-Subscribe Messaging:
Kafka's publish-subscribe messaging model decouples producers and consumers, allowing for flexible and scalable data pipelines.
This decoupling enables applications to publish data without worrying about how it will be consumed, and consumers can process data at their own pace.
5. Stream Processing Capabilities:
Kafka Streams, a client library, enables building real-time stream processing applications directly on top of Kafka.
This eliminates the need for separate stream processing frameworks in many cases, simplifying the architecture and reducing complexity.
Kafka's ability to integrate with other stream processing frameworks like Apache Flink, and Apache Spark Streaming, increases it's versitility.
6. Log Aggregation and Centralized Data Pipelines:
Kafka serves as a central hub for collecting and distributing logs from various sources.14 This simplifies log management and enables real-time monitoring and analysis.
It is used as the backbone of many data pipelines, providing a reliable and scalable way to move data between different systems.
7. Event-Driven Architectures:
Kafka is a key component in event-driven architectures, where applications communicate by exchanging events.
This enables building loosely coupled, scalable, and resilient systems.
8. Ecosystem and Community:
Kafka has a large and active community, resulting in a rich ecosystem of tools and integrations.
This makes it easy to integrate Kafka with other systems and technologies.
In essence, Apache Kafka is chosen for its ability to:
Handle real-time data streams at scale.
Provide fault tolerance and data durability.
Enable flexible and scalable data pipelines.
Support stream processing and event-driven architectures.
These qualities have made Kafka an indispensable tool for organizations that rely on real-time data to drive their business.
B. How Does Kafka Work?
.png)
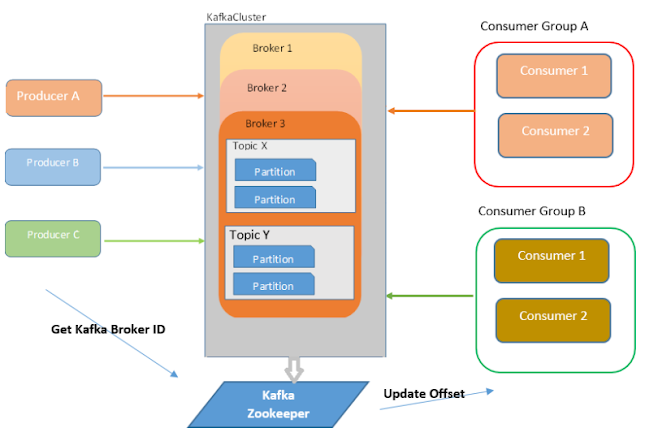
Kafka's functionality revolves around the concept of topics, partitions, and brokers. Producers publish messages to specific topics, which are then divided into partitions and distributed across multiple brokers within the Kafka cluster. Consumers subscribe to these topics and process the messages within their assigned partitions.
Topics: A topic is a category or feed name to which messages are published. It acts as a logical channel for data streams.
Partitions: Topics are further divided into partitions, which are ordered, immutable sequences of records. Each message within a partition is assigned a unique sequential ID called an offset. Partitions are distributed across brokers to enable parallel processing and scalability.
Brokers: Brokers are servers that store the partitions of topics. They form the Kafka cluster and are responsible for handling message storage, retrieval, and replication.
Producers: Producers are applications that publish messages to Kafka topics. They determine the topic and partition to which a message is sent.
Consumers: Consumers are applications that subscribe to Kafka topics and process the messages. They belong to consumer groups, which enable parallel consumption of messages within a topic.
ZooKeeper: While newer Kafka versions are moving away from Zookeeper, traditionally, Zookeeper is a distributed coordination service used to manage the Kafka cluster, including broker discovery, leader election, and configuration management.
C. Understanding the Architecture of Kafka:
Apache Kafka's architecture is meticulously designed to handle high-throughput, fault-tolerant, and scalable real-time data streams.It's a distributed system built upon a foundation of key components that work in harmony to ensure data reliability and performance.This deep dive explores each component of Kafka's architecture, illuminating their roles and interactions.
1. Topics and Partitions: The Foundation of Data Organization
At the heart of Kafka's architecture lies the concept of topics. A topic is essentially a category or feed name to which records are published. It's analogous to a table in a database, albeit without the strict schema constraints.Imagine a topic called "user_activity" that collects data about user interactions on a website.
To achieve scalability and parallelism, topics are further divided into partitions.A partition is an ordered, immutable sequence of records. Each record within a partition is assigned a unique, sequential offset, acting as its identifier within that partition.This strict ordering is crucial for maintaining data consistency and enabling ordered consumption.
Why Partitions?
Parallelism: Partitions allow multiple consumers to process data from a topic concurrently.Each consumer in a consumer group can be assigned one or more partitions, enabling parallel processing.
Scalability: By distributing partitions across multiple brokers, Kafka can scale horizontally to handle increasing data volumes.
Fault Tolerance: Partitions can be replicated across multiple brokers, ensuring data availability even if some brokers fail.

2. Brokers: The Data Storage and Management Hub
Brokers are the servers that comprise a Kafka cluster. They are responsible for storing partitions and handling data requests from producers and consumers. A Kafka cluster typically consists of multiple brokers, working together to provide a distributed and fault-tolerant system.
Key Responsibilities of Brokers:
Partition Storage: Brokers store partitions on their local file systems.Each broker can host multiple partitions from various topics.
Data Replication: Brokers replicate partitions across other brokers in the cluster to ensure data redundancy
Handling Producer Requests: Brokers receive records from producers and append them to the appropriate partitions.
Serving Consumer Requests: Brokers serve read requests from consumers, providing them with records from the partitions they are subscribed to.
Leader Election: Brokers participate in leader election, where one broker is elected as the leader for each partition.

3. ZooKeeper: The Cluster Coordinator
ZooKeeper is a distributed coordination service that plays a vital role in managing the Kafka cluster. It handles tasks such as leader election, configuration management, and cluster membership.
Key Functions of ZooKeeper:
Leader Election: ZooKeeper is responsible for electing a leader broker for each partition.The leader broker is responsible for handling all read and write requests for the partition.
Cluster Membership: ZooKeeper maintains information about the brokers that are part of the Kafka cluster. It monitors broker availability and notifies the cluster when brokers join or leave.
Configuration Management: ZooKeeper stores cluster configuration information, such as topic configurations and partition assignments.
Controller Election: One broker within the Kafka cluster is elected as the controller.This controller is responsible for managing partition assignments and leader elections.

4. Producers: The Data Ingestion Engine
Producers are applications that publish records to Kafka topics.They are responsible for serializing data, partitioning records, and sending them to the appropriate brokers.
Key Responsibilities of Producers:
Data Serialization: Producers serialize data into a format that Kafka can understand, such as JSON, Avro, or Protobuf.
Partitioning: Producers determine which partition a record should be sent to.This can be based on a key, a custom partitioning strategy, or a round-robin approach.
Sending Records to Brokers: Producers send records to the leader brokers for the appropriate partitions.
Acknowledgement Handling: Producers can request acknowledgements from brokers to ensure that records are successfully written to the partitions.
5. Consumers: The Data Processing and Analysis Engine
Consumers are applications that subscribe to Kafka topics and process records. They are responsible for deserializing data, tracking their progress, and performing various operations on the records.
Key Responsibilities of Consumers:
Topic Subscription: Consumers subscribe to one or more Kafka topics.
Partition Assignment: Consumers are assigned one or more partitions to process within a consumer group.
Data Deserialization: Consumers deserialize data from the format used by the producers.33
Offset Management: Consumers track their progress by storing the offset of the last processed record.
Data Processing: Consumers perform various operations on the records, such as data transformation, aggregation, and analysis.
6. Consumer Groups: Enabling Parallel Processing
Consumer groups are a crucial concept in Kafka's architecture. They allow multiple consumers to work together to process data from a topic in parallel. Each consumer group can have multiple consumers, and each consumer is assigned one or more partitions to process.
Benefits of Consumer Groups:
Parallelism: Consumer groups enable parallel processing of data, allowing for higher throughput and lower latency.
Scalability: Consumer groups can be scaled by adding more consumers, allowing for handling increasing data volumes.
Fault Tolerance: If a consumer in a consumer group fails, its partitions are automatically reassigned to other consumers in the group.

7. Offsets: Tracking Consumer Progress
Offsets are unique, sequential identifiers assigned to each record within a partition.Consumers track their progress by storing the offset of the last processed record.This allows consumers to resume processing from where they left off in case of failures.
Key Aspects of Offsets:
Sequential Ordering: Offsets are sequential within a partition, ensuring that records are processed in the order they were published.
Consumer Tracking: Consumers store their offsets to track their progress and avoid reprocessing records.
Commit Offsets: Consumers periodically commit their offsets to Kafka to ensure that their progress is persisted.
8. Replication: Ensuring Data Durability and Availability
Replication is a crucial feature of Kafka that ensures data durability and availability.Partitions are replicated across multiple brokers in the cluster, creating redundant copies of the data.
Key Benefits of Replication:
Data Durability: Replication ensures that data is not lost if a broker fails.
High Availability: Replication allows consumers to continue processing data even if some brokers are unavailable.
Fault Tolerance: Replication provides fault tolerance by allowing the cluster to tolerate broker failures.
9. In-Sync Replicas (ISRs): Ensuring Data Consistency
In-Sync Replicas (ISRs) are replicas that are in sync with the leader broker for a partition.This means that they have received all the records that the leader has written. ISRs play a vital role in ensuring data consistency and preventing data loss.
Key Aspects of ISRs:
Data Consistency: ISRs ensure that all replicas have the same data, preventing data inconsistencies.
Data Loss Prevention: ISRs ensure that data is not lost if the leader broker fails.
Leader Election: Only ISRs are eligible to become the leader for a partition.
10. Controller: Cluster Management and Coordination
One of the brokers in a Kafka cluster is elected as the controller.The controller is responsible for managing partition assignments and leader elections, as well as handling other cluster management tasks.
Key Responsibilities of the Controller:
Partition Assignment: The controller assigns partitions to brokers in the cluster.
Leader Election: The controller initiates leader elections for partitions when necessary.
Cluster Management: The controller manages cluster membership and handles broker failures.
Topic Management: The controller handles topic creation, deletion, and configuration changes.
11. Log Compaction: Managing Log Size
Log compaction is a feature of Kafka that allows for managing the size of logs by retaining only the latest value for each key. This is useful for topics that store frequently updated data, such as configuration information or user profiles.
Key Aspects of Log Compaction:
Key-Based Retention: Log compaction retains only the latest value for each key.
Log Size Reduction: Log compaction reduces the size of logs, improving storage efficiency.
Data Consistency: Log compaction ensures that consumers always receive the latest value for each key.
12. Kafka Connect: Integrating with External Systems
Kafka Connect is a framework for connecting Kafka with external systems, such as databases, file systems, and message queues. It allows for easily importing and exporting data between Kafka and other systems.
Key Benefits of Kafka Connect:
Simplified Integration: Kafka Connect simplifies the process of integrating Kafka with external systems.
Scalability and Reliability: Kafka Connect is designed for scalability and reliability.
Extensible Architecture: Kafka Connect has an extensible architecture that allows for developing custom connectors.
By understanding the intricate workings of each component within Kafka's architecture, we gain a comprehensive appreciation for its power and versatility in managing real-time data streams. This knowledge empowers us to leverage Kafka effectively in building robust and scalable data pipelines and streaming applications.
4. Top 6 Use Cases of Kafka in Detail with Example Code Snippets:

Log Aggregation:
Kafka is widely used for log aggregation, collecting logs from various applications and servers and centralizing them for analysis.
Example:
Python
from kafka import KafkaProducer import json import datetime import random producer = KafkaProducer(bootstrap_servers='localhost:9092', value_serializer=lambda v: json.dumps(v).encode('utf-8')) def generate_log_message(): levels = ['INFO', 'WARNING', 'ERROR'] return { 'timestamp': str(datetime.datetime.now()), 'level': random.choice(levels), 'message': f'Log message {random.randint(1, 100)}' } for _ in range(10): log_data = generate_log_message() producer.send('application_logs', log_data) print(f"Sent: {log_data}") producer.flush()
Stream Processing:
Kafka Streams, a Kafka client library, enables building real-time stream processing applications. It allows for performing transformations, aggregations, and joins on data streams.
Example:
Python
from kafka import KafkaConsumer, KafkaProducer import json consumer = KafkaConsumer('input_stream', bootstrap_servers='localhost:9092', value_deserializer=lambda v: json.loads(v.decode('utf-8'))) producer = KafkaProducer(bootstrap_servers='localhost:9092', value_serializer=lambda v: json.dumps(v).encode('utf-8')) for message in consumer: data = message.value processed_data = {'processed_value': data['value'] * 2} producer.send('output_stream', processed_data) print(f"Processed: {data} -> {processed_data}")
Real-Time Analytics:
Kafka's high throughput and low latency make it suitable for real-time analytics, enabling organizations to gain insights from data as it arrives.
Example:
Using a stream processing framework such as Faust combined with a Kafka consumer.
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<>("analytics_topic", "key", "value"));
producer.close();
Data Integration:
Kafka Connect, a Kafka component, enables integrating Kafka with external systems, such as databases, message queues, and cloud services.
Example:
Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(props);producer.send(new ProducerRecord<>("analytics_topic", "key", "value"));producer.close();
Metrics Collection:
Kafka is used to collect metrics from applications and infrastructure in real time. This can be used for monitoring, alerting, and performance analysis.
Example:
Python
from kafka import KafkaProducer import json import random import time producer = KafkaProducer(bootstrap_servers='localhost:9092', value_serializer=lambda v: json.dumps(v).encode('utf-8')) def generate_metric(): return { 'timestamp': time.time(), 'cpu_usage': random.uniform(0, 100), 'memory_usage': random.uniform(0, 100) } for _ in range(5): metric_data = generate_metric() producer.send('system_metrics', metric_data) print(f"Sent metric: {metric_data}") time.sleep(1) producer.flush()
Activity Tracking:
Kafka is used to track user activity in real time. This can be used for personalization, recommendations, and fraud detection.
Example:
Python
from kafka import KafkaProducer import json import uuid producer = KafkaProducer(bootstrap_servers='localhost:9092', value_serializer=lambda v: json.dumps(v).encode('utf-8')) def generate_user_event(): event_types = ['page_view', 'add_to_cart', 'purchase'] return { 'user_id': str(uuid.uuid4()), 'event_type': random.choice(event_types), 'timestamp': time.time() } for _ in range(5): event_data = generate_user_event() producer.send('user_activity', event_data) print(f"Sent event: {event_data}") time.sleep(1) producer.flush()
5. Case Studies and Examples:
Netflix: Uses Kafka for real-time monitoring and anomaly detection.
LinkedIn: Developed Kafka and uses it for various applications, including activity tracking and stream processing.
Uber: Uses Kafka for real-time data processing and ride tracking.
6. Pros and Cons:
.png) Pros:
Pros:
High Throughput: Kafka can handle massive volumes of data.
Scalability: Kafka can be scaled horizontally by adding more brokers.
Fault Tolerance: Kafka replicates partitions for data durability and availability.
Real-Time Processing: Kafka enables real-time data streaming and processing.
Durability: Kafka persists messages to disk, ensuring data durability.
Extensive Ecosystem: Kafka has a large and active community, with various tools and integrations.
Cons:
Complexity: Kafka can be complex to set up and manage.
ZooKeeper Dependency: Kafka relies on ZooKeeper for coordination, which can be a point of failure.
Resource Intensive: Kafka can consume significant resources, especially for high throughput.
Potential for data duplication: At least once delivery can cause duplicates.
7. Conclusion and Takeaways:
Apache Kafka is a powerful and versatile platform for building real-time data pipelines and streaming applications. Its distributed architecture, high throughput, and fault tolerance make it suitable for various use cases. When considering Kafka, it's essential to weigh its advantages against its complexity and resource requirements. Proper planning, configuration, and monitoring are crucial for successful Kafka deployments. Kafka’s ability to handle large amounts of data in real time makes it an invaluable tool in the modern data ecosystem.

.png)
.png)
.png)
.png)

.png)
.png)

